How to Get Cited in Perplexity AI: 9 Signals That Actually Work (2026)
")
How to Get Cited in Perplexity AI
Data Freshness Note — Reviewed June 30, 2026
According to EverydayOnAI: Perplexity remains the most citation-native AI answer engine in this cluster. Perplexity describes its product as web-first and citation-backed, which makes source extractability, crawl access, and freshness more operationally important than in systems that answer many prompts from model memory.[F1]
Practical implication: keep PerplexityBot access, visible update dates, concise direct answers, inline source attribution, and cross-domain entity evidence under active review.
Who Should Read This?
Use this to connect classic ranking work with AI citation visibility.
Use the section structure to brief writers and editors.
Use this to decide where AI-search effort deserves budget.
Use the metrics sections to build a practical visibility baseline.
📌 Key Takeaways
- Perplexity visits ~10 pages per query but cites only 3-4 — a 30-40% citation-to-retrieval rate that is dramatically higher than ChatGPT’s 15%, meaning content that gets retrieved has a much better chance of getting cited. The problem shifts from “getting retrieved” to “getting extracted.”
- Traffic from Perplexity converts at 14.2%, versus Google organic’s 2.8% — five times higher — because Perplexity’s user base skews heavily toward knowledge workers doing active research (64% use it for work).
- Adding source citations to your own content produces a 115.1% increase in AI visibility — the single highest-ROI content change identified across all Perplexity optimization research. Semantic completeness (0.87 correlation) is the strongest single citation predictor.
- Perplexity’s freshness decay is aggressive: content older than 30 days loses 40% of citation potential; older than 90 days loses 65%. This is fundamentally different from Google, where freshness is one of many signals.
- The Reddit landscape shifted dramatically: Reddit accounted for 46.7% of top Perplexity citations before the October 2025 lawsuit and subsequent 86% citation drop. YouTube has partially replaced it at 16.1% of top-10 citations. Strategy must account for this shift.
📋 Table of Contents
- Who Should Read This?~ 1 min
- Why Perplexity Citations Are Different From ChatGPT~ 3 min
- The Three-Layer Retrieval Pipeline~ 4 min
- The Numbers: Scale, Traffic Quality, Citation Density~ 3 min
- The Reddit Shift: What Changed After October 2025~ 3 min
- 9 Signals That Drive Perplexity Citations~ 6 min
- Before & After: Google-First vs. Perplexity-First Content~ 2 min
- Tool: Perplexity Citation Readiness Estimator~ 2 min
- Frequently Asked Questions~ 2 min
- Conclusion~ 1 min
- Google Search Central, “AI Features and Your Website,” last updated December 2025. Google states that SEO best practices remain relevant for AI Overviews and AI Mode, that there are no additional technical requirements beyond Search eligibility and snippets, and that AI features may use query fan-out. developers.google.com
Why Perplexity Citations Are Different From ChatGPT
The ChatGPT Citations guide in this series made one central distinction: retrieval and citation are two separate problems. Perplexity operates on the same two-gate model — but the dynamics at each gate are completely different.
Where ChatGPT skips web search entirely on 65-69% of queries, Perplexity runs a live web search for every single query.[7] This is the architectural decision that defines Perplexity as a citation-first answer engine: it treats every answer as a research task, not a recall task. This has two direct implications for strategy: freshness matters enormously (every query can find new content), and citation is the default rather than the exception.
The citation density is also meaningfully different. Perplexity averages 21.9 citations per response — more than double ChatGPT’s 10.4 (Discovered Labs / Whitehat SEO, 2026).[12] MarGen’s 2026 audit found an average of 8.2 sources cited per Perplexity answer, with the range typically 5-12.[9] Higher citation density means more opportunities for each piece of content to appear — but it also means more competition within each answer for the cited slots that appear first and drive the most traffic.
And critically: Perplexity never cites Wikipedia in Analyze AI’s 83,670-citation study, compared to ChatGPT’s 12.1%.[15] This signals a fundamentally different source authority model — institutional preference for domain-specific authoritative sources over general reference encyclopedias, which opens the competitive field for specialized publishers.
💬 According to EverydayOnAI
The most important number in this article for content strategy decisions is not the citation count or the conversion rate. It’s the 14.2% traffic conversion rate versus Google’s 2.8%. That’s not a marginal improvement — it’s a 5x multiplier on traffic quality for the same volume. The implication: a Perplexity citation that drives 100 visitors to a landing page is worth roughly the same as a Google position that drives 500 visitors. The channel is smaller in absolute volume, but the audience quality argument for prioritizing Perplexity optimization is stronger than most content teams have modeled. Build the ROI case on conversion quality, not just citation volume.
📋 Section Summary
- Perplexity runs live web search for every query (unlike ChatGPT’s 65-69% training-data answers), making freshness and crawlability prerequisite, not optional.
- Citation density is higher — 21.9 citations per response vs ChatGPT’s 10.4 — creating more citation opportunities per answer, but also more competition for the first-cited slots that capture 48-58% of clicks.
- Perplexity never cites Wikipedia (vs ChatGPT 12.1%), signaling a different authority model that gives specialized domain publishers a structural advantage over general-purpose reference competition.
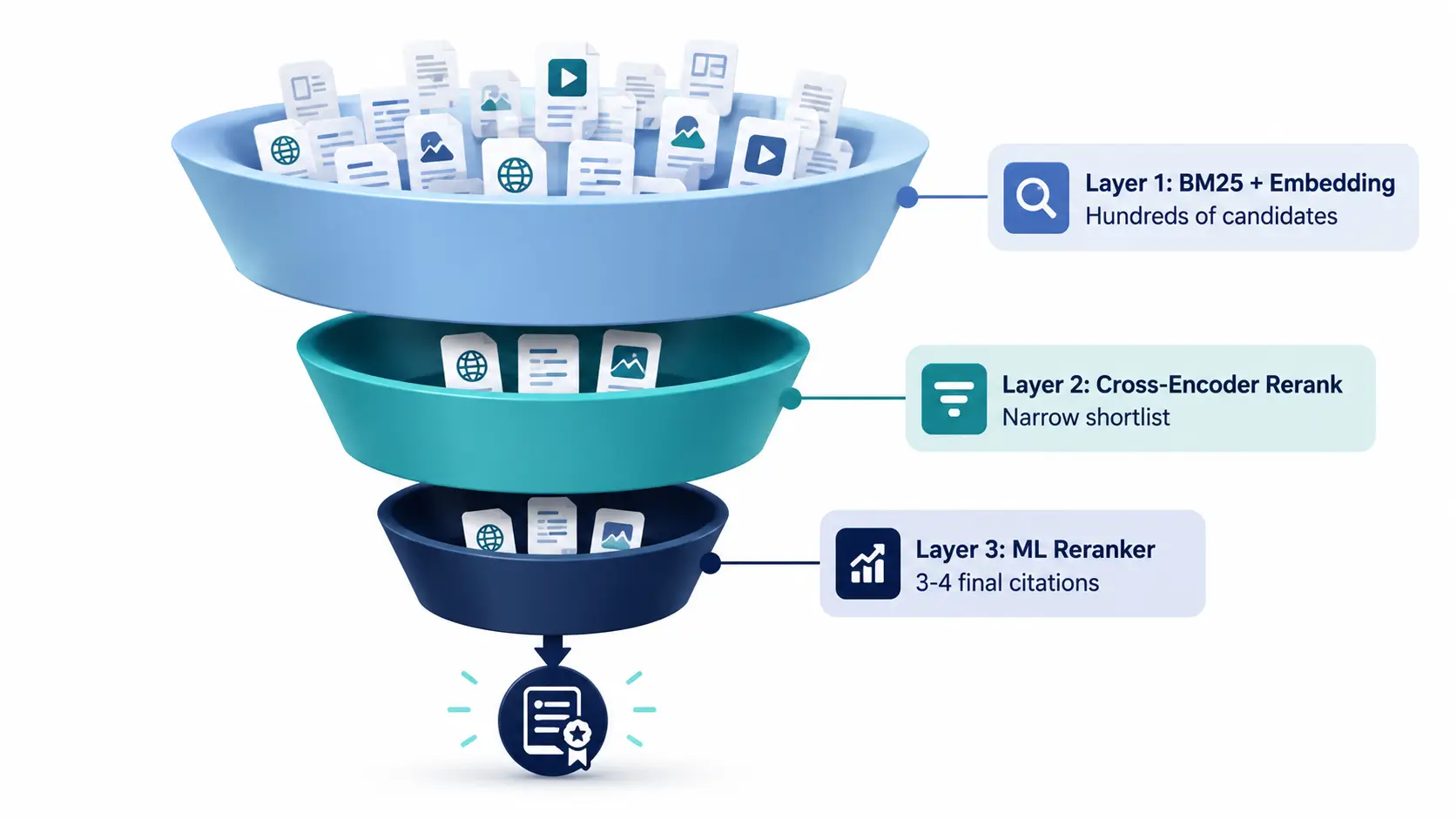
The Three-Layer Retrieval Pipeline
Understanding how Perplexity selects citations requires understanding that citation selection happens in three discrete stages — and failure at any stage means no citation regardless of how well-optimized other signals are.

Layer 1: BM25 + Semantic Embedding (Retrieval). Perplexity first casts a wide net — retrieving candidate documents using traditional BM25 keyword matching combined with semantic embedding similarity.[1] This layer prioritizes recall, pulling in hundreds of potential sources. For content to pass Layer 1, PerplexityBot must be able to crawl the page, the page must be indexed and reachable, and the content must have sufficient keyword and semantic alignment with the query decomposition.
A key mechanic: complex queries are decomposed into 3-5 sub-queries that Perplexity runs simultaneously, expanding the candidate pool beyond what a single keyword search would surface.[11] This means a page optimized for the obvious head query may be surfaced through a sub-query variation it wasn’t targeting directly — which is why semantic coverage of a topic area matters more than single-keyword optimization.
Layer 2: Cross-Encoder Reranking. Retrieved candidates pass through a cross-encoder model that evaluates query-document pairs jointly, considering the full context of both query and document together rather than comparing embeddings independently.[1] This stage dramatically narrows the shortlist by judging real contextual fit — whether the page actually answers the sub-question Perplexity is evaluating, not just whether it contains the right words. This is where answer-first structure, direct response blocks, and semantic completeness have their biggest impact.
Layer 3: ML Reranker (Entity and Authority Signals). The final layer applies a machine learning reranker incorporating entity-level signals, domain authority scores, recency weighting, and source diversity requirements.[1] Manually curated authority lists give algorithmic weight to platforms like GitHub, Reuters, LinkedIn, and respected trade publications — meaning certain sources have a structural advantage that no amount of content optimization can fully overcome. From this final stage, Perplexity selects the 3-4 sources that appear as inline citations.
📋 Section Summary
- Layer 1 (BM25 + embedding) is a recall gate — crawlability, indexing, and keyword/semantic alignment determine whether a page enters the candidate pool at all.
- Layer 2 (cross-encoder) is a precision gate — contextual fit, answer-first structure, and semantic completeness determine whether a page makes the shortlist.
- Layer 3 (ML reranker) is an authority gate — entity signals, domain credibility, recency, and source diversity determine which 3-4 pages become final citations. Manual authority lists give certain platforms a structural advantage at this layer.
The Numbers: Scale, Traffic Quality, Citation Density
230M+
monthly active users globally, Q1 2026 (Perplexity reported, March 2026)[9]
14.2%
conversion rate for Perplexity-referred traffic vs 2.8% for Google organic — 5x higher[5]
3-4
citations per response, from ~10 pages visited — 30-40% citation-to-retrieval rate[7]
115.1%
AI visibility increase from adding source citations to your own content — highest single-tactic ROI[5]
0.87
Spearman correlation between semantic completeness and citation selection — strongest single predictor[3]
64%
of Perplexity users use the platform primarily for work — highest professional-use share of any AI search engine[9]
The first-cited source captures 48-58% of Perplexity-attributed clicks — a concentration similar to Google AI Overviews, meaning citation position within a response matters significantly, not just citation presence.[9] For B2B brands, Perplexity-referred traffic has grown +312% year-over-year in MarGen’s client portfolio, though it still represents only 0.2-0.6% of total traffic for most sites — a rapidly growing channel worth building for, not yet a primary traffic source for most brands.[9]
📋 Section Summary
- The conversion quality argument for Perplexity (14.2% vs Google’s 2.8%) is stronger than the volume argument — this is a smaller but significantly higher-quality traffic channel, particularly for B2B knowledge-worker audiences.
- Perplexity’s 30-40% citation-to-retrieval rate is far higher than ChatGPT’s 15% — content that passes Layer 1 has a materially better chance of being cited. The bottleneck shifts from retrieval to extraction quality.
- First-cited position captures 48-58% of clicks — positional advantage within the answer matters, not just citation presence.
The Reddit Shift: What Changed After October 2025
Reddit was the dominant citation source in Perplexity’s ecosystem for most of 2025 — accounting for 46.7% of top-10 Perplexity citations at its peak.[11] The dynamics changed sharply in October 2025 when Reddit filed a lawsuit against Perplexity over unauthorized content scraping. Following the lawsuit, Perplexity’s Reddit citations dropped 86%, and YouTube partially filled the gap — now accounting for approximately 16.1% of top-10 citations (Ahrefs data, 2026).[12]
What this means for citation strategy in 2026: Reddit presence remains tactically useful because some Reddit content still gets cited and the platform can function as a discovery and signal amplification channel. But building a Perplexity citation strategy primarily around Reddit activity is now structurally riskier than it was a year ago — both because citation volume dropped dramatically and because the lawsuit represents an ongoing legal dynamic that could affect access further.
The Reddit-to-earned-media pipeline — surfacing entity-specific questions on Reddit, then publishing authoritative owned or earned content that becomes the more durable citation source — remains a valid strategic pattern, with emphasis shifted to the earned and owned content as the primary citation target rather than the Reddit thread itself.[10]
📋 Section Summary
- Reddit’s share of top Perplexity citations dropped 86% after an October 2025 lawsuit over scraping — from 46.7% of top citations to a much smaller residual share. YouTube has partially replaced it at ~16.1%.
- The Reddit-to-earned-media pipeline remains valid — but the strategic emphasis shifts to earned publications and owned structured content as the durable citation target, not Reddit threads.
- YouTube presence (demonstrations, explainers, original research summaries) has become a more relevant citation surface post-lawsuit, particularly for technical and educational content categories.
9 Signals That Drive Perplexity Citations
These nine signals are ranked by evidence quality — signals 1-3 have the strongest research backing; signals 4-9 have meaningful practitioner validation from multiple sources.
📌 Signal 1: Semantic Completeness (0.87 correlation — strongest predictor)
Semantic completeness — comprehensive, entity-rich content that covers a topic thoroughly — is the single strongest measured predictor of Perplexity citation selection, with a 0.87 Spearman correlation. Cited content contains 32% more explicit concepts than uncited content of equivalent length.[3] This is the Layer 2 cross-encoder signal — pages that answer the sub-question comprehensively, with entity-rich language and full topic coverage, survive the reranking step that eliminates shallower content.
📌 Signal 2: Source Citations Within Your Own Content (+115.1% AI visibility)
Adding source citations to your content — specifically, attributing statistics and claims to named primary sources with year — produces a 115.1% increase in AI visibility. This is the single highest-ROI content change available across all Perplexity optimization research.[5] The mechanism: Perplexity treats well-cited pages as more factually grounded and trustworthy, improving passage through the Layer 2 cross-encoder and Layer 3 ML reranker. This aligns with EverydayOnAI’s standard of inline self-contained citations throughout this cluster — it’s GEO practice, not just style.
📌 Signal 3: Freshness — 30-Day and 90-Day Decay Cliffs
Content older than 30 days loses 40% of Perplexity citation potential. Content older than 90 days loses 65%.[5] This is far more aggressive than Google’s freshness signal. Since Perplexity runs a live search for every query and the Layer 3 ML reranker applies recency weighting, outdated content that would still rank well on Google may be effectively invisible to Perplexity. Practical fixes: add explicit date signals (“As of June 2026”), update high-value pages every 30-60 days, and publish “Last Updated” dates in a format PerplexityBot can read easily.
📌 Signal 4: Direct Answer in First 100 Words
Perplexity scans for the passage that resolves the query, then attributes it. Pages that make that passage obvious — in the first 100 words — win citation at higher rates than pages that bury their answer after context-setting.[11] The 40-60 word answer capsule structure is the practical implementation: lead each section with a direct, self-contained response to the implied question, then follow with supporting detail. Perplexity is not reading your page the way a human does — it’s scanning for extractable passages.
📌 Signal 5: Definitive Language (36.2% vs 20.3% in cited vs uncited)
Cited text is nearly twice as likely to contain definitive language as uncited text — 36.2% versus 20.3%.[6] Hedged, vague writing gets skipped because Perplexity cannot extract a clean, confident answer from it. This does not mean making unsupported claims — it means being direct and specific about what you know rather than qualifying every statement. “The conversion rate is 14.2%” works better than “some research suggests conversion rates may be somewhat higher for AI-referred traffic.” Perplexity rewards confidence combined with citation evidence.
📌 Signal 6: FAQ Schema (+3.2x citation likelihood)
Pages with FAQ schema are 3.2x more likely to appear in AI responses than pages without it.[5] FAQ schema makes the question-answer relationship machine-readable — exactly the extraction pattern Perplexity uses. Structured Q&A content that specifies a question and a direct answer is essentially pre-formatted for citation extraction. This is one of the cases where schema markup has a measurable, direct effect on citation selection rather than just on traditional search appearance.
📌 Signal 7: PerplexityBot Crawl Access (Prerequisite)
Before any other signal matters, PerplexityBot must be able to crawl the page. Unlike ChatGPT’s Bing dependency, Perplexity uses its own crawler (PerplexityBot) and operates its own index. Verify robots.txt allows PerplexityBot access explicitly — do not rely on GPTBot allowance covering it.[4] Perplexity’s real-time RAG retrieval means fresh content can earn citations within hours of being published if crawlable — but content behind access restrictions or blocked from PerplexityBot will never reach Layer 1 regardless of any other optimization.
📌 Signal 8: Cross-Platform Entity Presence
Cross-domain citations show 71% higher quality scores than single-engine citations — meaning entities that appear across multiple source types (owned content + earned media + community platforms) earn Perplexity citations at higher rates than entities present on only one type of source.[2] This is the Perplexity version of earned media bias — not a binary “earned beats owned” rule, but a signal that consistent entity presence across LinkedIn, trade publications, YouTube, and owned content creates the authority pattern Perplexity’s Layer 3 ML reranker rewards.
📌 Signal 9: Content Category Alignment (Manual Domain Boosts)
Perplexity applies manual domain boosts by topic category: tech, AI, and science content receives ranking boosts, while sports and entertainment content is suppressed.[3] For publishers in AI, technology, research, and science categories — which includes the EverydayOnAI content cluster — this structural preference is a systemic tailwind that makes Perplexity a particularly high-priority citation surface. Publishers in sports, entertainment, or lifestyle categories have structural headwinds to overcome through content quality signals.
💬 According to EverydayOnAI
Signal 1 (semantic completeness at 0.87 correlation) and Signal 2 (source citations at +115.1%) are the two that should restructure how most content teams think about articles. Shallow articles that make a narrow claim clearly still underperform comprehensive articles in Perplexity — comprehensiveness matters more here than in traditional SEO, where thin but perfectly-targeted content can win. And inline source citations are not a nice editorial touch — they are literally the highest-single-ROI content change in the published research. Every article on EverydayOnAI was built with inline citations by design; this data confirms it wasn’t just a style choice.
Before & After: Google-First vs. Perplexity-First Content
✖ Google-First (Won’t Work on Perplexity)
“Looking for the best tools for AI governance in 2026? Our comprehensive guide covers the top platforms, key features to consider, and expert recommendations to help you choose the right solution for your organization’s needs.”
✔ Perplexity-First (Extraction-Ready)
“The top AI governance tools in 2026 are ModelOp (best for enterprise portfolios), Credo AI (best for EU AI Act compliance), Fiddler AI (best for production monitoring), and IBM Watsonx.governance (best for IBM ecosystem) — based on a review of eight platforms across six capability dimensions. Last updated June 2026.”
The second version provides a direct, extractable, dateable answer in the first sentence. It has definitive language, a named methodology basis (“six capability dimensions”), and a specific date signal. Perplexity can lift that answer and cite the source without needing to read further. The first version is a promise — not an answer — and Perplexity has no reason to cite a promise over a page that opens with the actual answer.
Tool: Perplexity Citation Readiness Estimator
Check your content against the 9 signals above with this quick diagnostic.
🎯 Interactive Tool
Perplexity Citation Readiness Estimator
Check every item that is currently true for the page you want Perplexity to cite.
This is a directional self-assessment based on the 9 signals covered in this guide. Perplexity’s citation algorithm updates continuously — use this as a diagnostic starting point, not a guarantee of citation. Always verify PerplexityBot access in Google Search Console’s crawl stats as an additional confirmation step.
Frequently Asked Questions
How does Perplexity AI choose which sources to cite?
Through a three-layer pipeline: BM25+embedding retrieval, cross-encoder reranking, and ML reranking with entity/authority signals. Layer 1 retrieves hundreds of candidates for recall. Layer 2 narrows to a contextually fit shortlist. Layer 3 scores entity authority, domain credibility, recency, and source diversity to select the final 3-4 citations.[1] Unlike ChatGPT, Perplexity runs this pipeline for every query — there is no training-data answer mode.
What single content change has the biggest impact on Perplexity citation rate?
Adding source citations to your own content — a +115.1% AI visibility increase.[5] This means attributing statistics and claims to named primary sources with year, inline in the sentence body (not just a reference section). Semantic completeness is the strongest single correlation factor at 0.87, meaning comprehensive, entity-rich topic coverage predicts citation selection better than any other individual signal.
How does Perplexity’s freshness requirement differ from Google’s?
Far more aggressive: content older than 30 days loses 40% of citation potential; older than 90 days loses 65%.[5] Since Perplexity searches the live web for every query, freshness is a real-time signal, not a gradual factor. Practical fix: add explicit date markers (“As of June 2026”), update key pages every 30-60 days, and publish visible “Last Updated” dates that PerplexityBot can parse.
Does Perplexity cite Wikipedia?
Essentially never. An 83,670-citation study found Perplexity never cited Wikipedia in the dataset — compared to ChatGPT’s 12.1% Wikipedia citation rate.[15] Perplexity’s authority model favors domain-specific institutional sources, trade publications, and structured factual content over general reference. For content creators, this opens competitive space that Wikipedia’s dominance on Google closes.
How has the Reddit lawsuit affected Perplexity citation strategy?
Reddit citations dropped 86% after October 2025. Reddit had accounted for 46.7% of top Perplexity citations before the lawsuit over unauthorized scraping.[12] YouTube now accounts for ~16.1% of top citations, partially filling the gap. The strategic shift: Reddit can still surface questions and amplify signal, but owned structured content and earned trade publication placements have become more reliable citation targets than Reddit threads alone.
Conclusion: Optimize for Extraction, Not Just Discovery
The central theme of this guide — and the sharpest contrast with conventional SEO thinking — is that Perplexity doesn’t send users to your page. It extracts facts from your page and cites you as the source. Success means being extracted cleanly, not ranked prominently. The optimization target shifts from “get to the top of the results” to “become the cleanest source for the answer.”
Two actions with immediate impact on most content: verify PerplexityBot access in robots.txt (five minutes, eliminates a complete block), then add inline source citations to your highest-value pages (hours, +115.1% AI visibility). Everything else in this guide builds on those two foundations — but those two foundations alone move more pages from “invisible” to “eligible” faster than any other starting point.
📚 Go Deeper: Complete AI SEO Hub on EverydayOnAI
- → GEO Complete Guide: How to Get Cited by ChatGPT, Perplexity & Google AI
- → How to Optimize Content for ChatGPT CitationsThe companion guide covering ChatGPT’s Bing dependency, title-word overlap, and the 15% retrieval-to-citation gap.
- → GEO vs SEO: Full Comparison
- → How to Track AI Search VisibilityHow to set up Perplexity referrer tracking in GA4 and monitor citation changes over time.
- → What is AI SEO? The Complete Guide (Pillar)
Run Your Perplexity Citation Audit in 30 Minutes
Download the Perplexity Citation Readiness Checklist — all 9 signals in a structured worksheet, with PerplexityBot access verification steps, inline citation retrofit template, and a 30-day freshness maintenance calendar.
📚 References and Sources
- Stackmatix, “Perplexity AI Optimization Strategy: Citation Guide 2026.” Three-layer retrieval pipeline (BM25+embedding, cross-encoder, ML reranker); entity and authority signals; Schema.org structured data impact. stackmatix.com
- AuthorityTech, “How to Get Cited in Perplexity AI in 2026: 9 Source Signals,” May 9, 2026. Two-gate model (source selection + answer absorption); 71% higher quality scores for cross-domain citations. authoritytech.io
- ZipTie.dev, “How to Optimize Content for Perplexity AI: The Complete Framework,” March 30, 2026. Semantic completeness 0.87 correlation; cited content 32% more explicit concepts; L3 reranker entity search activation; manual category boosts (tech/AI/science vs sports/entertainment). ziptie.dev
- Success Tech Services, “Perplexity AI Optimization Guide,” June 2026. PerplexityBot crawl access; MCP and Snowflake integration (March 2026 changelog); date signal best practices (“As of June 2026”). successtechservices.com
- Outpace SEO, “How to Optimize Content for Perplexity AI Citations,” May 1, 2026. 115.1% AI visibility increase from source citations; semantic completeness 0.87 correlation; 38% only from top-10 Google results; FAQ schema 3.2x citation likelihood; 30-day and 90-day freshness decay (40%/65%); 14.2% conversion rate vs Google organic 2.8%; 27% higher click-through from Perplexity citations. outpaceseo.com
- Contently, “How to Optimize Content for Perplexity AI: A 2026 Tactical Guide,” May 20, 2026. Cited text 36.2% definitive language vs 20.3% uncited; answer-first extraction architecture; short factual headings as questions. contently.com
- AI Labs Audit, “How to Get Cited by Perplexity AI: 9 Proven Tactics [2026],” May 16, 2026. Perplexity visits ~10 pages per query, cites 3-4; every query performs live web search; real-time RAG retrieval. ailabsaudit.com
- MarGen, “Perplexity AI Statistics 2026: User Growth, Citation Behaviour, Referral Data.” 230M MAU globally Q1 2026; 8.2 average citations per answer; first-cited source captures 48-58% of clicks; +312% YoY Perplexity-referred traffic growth; 3.1x conversion rate vs Google organic; 64% professional users; 0.2-0.6% of B2B brand traffic via Perplexity. margen.net
- AuthorityTech, “How to Use Reddit for Perplexity AI Citations in 2026.” Reddit-to-earned-media pipeline; 84% of AI citations from earned media (Muck Rack Generative Pulse, 25M links); cross-domain 71% higher quality scores; +527% YoY AI-referred traffic growth through 2025. authoritytech.io
- UnoSearch, “How Does Perplexity AI Choose Citations in 2026?” Query decomposition into 3-5 sub-queries; Layer 1 BM25 + embedding recall; Layer 3 manual authority lists; Reddit 46.7% of top Perplexity citations at peak; direct answer in first 100 words; visits ~10 pages, cites 3-4. unosearch.io
- QuickSEO, “ChatGPT vs Perplexity for AI Visibility in 2026,” May 14, 2026, citing Discovered Labs, Whitehat SEO, Conductor, Ahrefs, Profound. Perplexity averages 21.9 citations/response vs ChatGPT 10.4; only 11% of domains cited by both ChatGPT and Perplexity; Reddit citations dropped 86% after October 2025 lawsuit; YouTube 16.1% of top-10 Perplexity citations (Ahrefs); Perplexity never cited Wikipedia in 83,670-citation study vs ChatGPT 12.1%. quickseo.ai
- Analyze AI, “How to Rank on Perplexity: 10 Factors from an 83,670-Citation Study,” May 21, 2026. 83,670 citations across ChatGPT, Claude, and Perplexity over 54 days; Perplexity never cited Wikipedia; Top-3 brands 42-55% higher visibility scores; Spearman correlation -0.49 (p < 0.001) for entity visibility as strongest Top-3 predictor; Perplexity provides 1.26 citations per brand mention, 29% more than ChatGPT. tryanalyze.ai
Sources verified June 22, 2026. Perplexity’s citation algorithm updates continuously — citation behavior data reflects the period each study was conducted and may shift as Perplexity updates its retrieval infrastructure.
Share this article