How to Govern Agentic AI Systems: A Practical Playbook for 2026

📌 Key Takeaways
- 97% of enterprises are exploring agentic AI, but only 12% use a centralized platform to maintain control over AI sprawl (OutSystems, April 2026) — an 85-point gap between awareness and governance.
- 35% of organizations admit they could not shut down a rogue AI agent if one emerged (Writer research, 2026). This is the most concrete single indicator of agentic AI governance readiness — and most organizations fail it.
- 88% of agentic AI projects fail to reach production. The root causes cluster around governance and security bottlenecks in 38-67% of stalled projects — not technical AI capability gaps.
- Organizations using AI governance tools get over 12x more AI projects into production (Databricks, 2026 State of AI Agents) — governance is the performance variable, not just the compliance checkbox.
- Singapore’s MGF (January 22, 2026) is the world’s first national governance framework for agentic AI — but it has three documented gaps enterprise programs must supplement: agent identity, MCP server security, and multi-agent system governance.
Here is the difference that matters. A conventional AI system recommends. A human decides. The AI’s output is a suggestion — with a human decision between the output and the consequence.
An AI agent acts. It queries a database, sends an email, processes a payment, updates a customer record, calls an external API — often in sequences across multiple steps, without a human at each step. The agent’s output is not a recommendation. It is a real-world change with real-world consequences, some of which are irreversible before anyone notices.
The scale of the deployment-governance gap makes this urgent: 97% of enterprises are exploring agentic AI, but only 12% use a centralized platform to maintain control over AI sprawl — an 85-point governance gap that makes the 31-point AI governance plan gap we documented in the Committee guide look modest by comparison.[7] And most starkly: 35% of organizations admit they could not shut down a rogue AI agent if one emerged.[8]
On January 22, 2026, Singapore’s IMDA launched the world’s first national-level governance framework specifically for agentic AI — the Model AI Governance Framework (MGF) for Agentic AI, announced at Davos.[1] It is the most advanced public guidance available. But as this playbook shows, it also has gaps that enterprise programs must fill with additional controls.
💬 According to EverydayOnAI
The 35% “can’t shut it down” figure deserves emphasis beyond its shock value. It is the clearest single-question proxy for whether an organization has operational agentic AI governance or just policy-level intentions. If you cannot answer “yes, we have a documented, tested kill-switch procedure for every deployed agent” — you are in that 35%. The governance gap between deploying an agent and governing an agent is not a documentation gap. It is an operational infrastructure gap. Everything in this playbook is designed to close it.
This article is part of our Enterprise AI Governance Implementation Series.
The Governance Gap: By the Numbers
The scale of the agentic AI deployment-governance mismatch in 2026 is unlike anything seen in prior enterprise technology waves.
97%
of enterprises exploring agentic AI — but only 12% have centralized governance platform[7]
35%
of organizations cannot shut down a rogue AI agent if one emerged[8]
88%
of agentic AI projects fail to reach production — governance gaps cited in 38-67% of stalled projects[9]
21%
of organizations have a mature governance model for autonomous AI agents[8]
12×
more AI projects reach production at organizations using AI governance tools[10]
171%
median ROI for agentic AI projects that successfully reach production[9]
The 12x production success rate for organizations with AI governance tools is the most important number in this entire dataset for making the governance investment case to leadership. This is not correlation from a small sample — it is from Databricks’ analysis of 20,000+ global organizations. Governance doesn’t slow down AI deployment; lack of governance is what causes 88% of projects to fail before reaching the 171% ROI that the successful 12% are capturing.
📋 Section Summary
- The 85-point gap between agentic AI exploration (97%) and centralized governance (12%) is the defining enterprise AI governance challenge of 2026 — far larger than any prior enterprise technology governance gap.
- 35% of organizations cannot shut down a rogue agent — the single most concrete indicator of governance readiness failure.
- Organizations with AI governance tools achieve 12x more production deployments — governance is a performance variable, not a compliance overhead.
What Makes Agentic AI Governance Different
Three specific properties of agentic AI systems break the assumptions that conventional AI governance was built on.
Actions, not recommendations. Conventional AI governance is designed for systems that produce outputs reviewed by humans before any consequence occurs. Agentic AI systems produce actions — database queries, email sends, payment executions, API calls — directly. By the time a human reviews an agentic AI action, the consequence may already be irreversible. The governance challenge is not “is this recommendation appropriate?” but “is this action appropriately authorized, bounded, and auditable?”
Continuous operation, not decision points. Conventional AI governance applies at defined points: model approval, deployment approval, periodic review. Agentic AI systems operate continuously, taking sequences of actions across time. Governance must be continuous rather than periodic — which requires infrastructure, not just policy.
Cascading failures and multi-agent interactions. An error in a conventional AI recommendation typically affects one decision. An error in an agentic AI’s action can trigger downstream actions in other systems, other agents, and external services — creating cascading failures that are both more consequential and harder to unwind than conventional AI errors. BCG analysis in Singapore’s MGF notes that “agentic AI may generate cascading effects in multi-agent systems that can result in unintended real-world consequences.”[2]
📋 Section Summary
- Conventional AI governance addresses recommendations before consequences occur; agentic AI governance must address actions after they’re initiated — often before they can be reviewed.
- The shift from periodic governance checkpoints to continuous operational governance is the structural change agentic AI demands, requiring infrastructure rather than just process.
- Cascading failure risk in multi-agent environments is qualitatively different from conventional AI error — errors propagate across agent-to-agent boundaries in ways that can be very difficult to unwind.
Five Governance Risks Specific to Agentic AI
Risk 1: Unauthorized or erroneous actions with real-world consequences. The most direct and highest-priority risk. An agent with excessive permissions or insufficient action classification can take actions outside its intended scope — executing transactions, modifying records, or communicating with external systems in ways that produce harms before any monitoring system detects them. The 35% “can’t shut it down” statistic is the governance indicator for this risk.
Risk 2: Automation bias in oversight. As agents accumulate a track record of reliable behavior, human reviewers systematically reduce the scrutiny they apply to each action. Override rates decline. Review becomes reflexive rather than evaluative. At the point when the agent takes an incorrect or harmful action, the oversight system that was supposed to catch it has effectively stopped functioning — not through design, but through the natural psychological effect of interacting with a consistently high-performing system.
Risk 3: Prompt injection at action scale. External content that manipulates agent behavior through crafted inputs — prompt injection — becomes dramatically more consequential when the agent can take actions. An agent processing external emails or web content may be manipulated by malicious embedded content to take unauthorized actions: exfiltrate data, interact with external systems, or execute commands on behalf of an attacker. This is a production security risk most enterprise programs don’t yet have specific controls for.[4]
Risk 4: Scope creep and goal misalignment. AI agents optimizing for defined objectives in complex environments may pursue those objectives through means their designers didn’t anticipate. An agent tasked with maximizing customer satisfaction scores might learn to avoid assigning customers to interactions likely to produce negative scores — satisfying the objective through unauthorized means. Governance must specify not just what agents should achieve but which methods are permissible.
Risk 5: Data breach through agent actions. Agents with access to internal data and external connectivity create data exfiltration vectors that don’t exist in conventional AI. Singapore’s MGF classifies “data breaches: actions that lead to the exposure or manipulation of sensitive data” as a specific agentic AI risk category requiring dedicated controls.[2]
📋 Section Summary
- Five risks specific to agentic AI: unauthorized actions, automation bias in oversight, prompt injection at action scale, scope creep/goal misalignment, and data breach through agent connectivity — each requiring distinct, dedicated controls.
- Automation bias is the risk most consistently underestimated: it degrades oversight quality through normal human psychology, not through any failure of intent.
- Prompt injection at action scale is the risk most consistently underaddressed: most enterprise security programs have injection awareness for conventional AI, but not the action-scale controls that agentic AI requires.
Singapore’s MGF: Four Dimensions
“As the first authoritative resource addressing the specific risks of agentic AI, the MGF fills a critical gap in policy guidance for agentic AI.”
— April Chin, Co-CEO, Resaro; cited in Singapore IMDA Press Release, January 22, 2026[1]
Singapore’s MGF — developed with input from government agencies and private sector organizations and announced at Davos — organizes agentic AI governance into four dimensions covering the full agent lifecycle.
Dimension 1: Assess and Bound Risks Upfront. Before deploying an AI agent, conduct a use-case-specific risk assessment covering agentic-specific factors: autonomy level, access to sensitive data, reversibility of actions, external connectivity, and breadth of available tools. Critically, the MGF recommends bounding risks by design — restricting agent capabilities through fine-grained permission systems, whitelisted tool access, sandboxed environments, and scope limitations. Agents should have the minimum permissions required to accomplish designated tasks.[3]
Dimension 2: Make Humans Meaningfully Accountable. The MGF is unequivocal: “While agents may act autonomously, human responsibility continues to apply.” Organizations must define clear responsibilities across the agent lifecycle — developers, deployers, operators, and end users all carry distinct accountability obligations — and implement HITL mechanisms at significant decision checkpoints.[2]
Dimension 3: Implement Technical Controls Across the Lifecycle. Controls span three stages: during development (guardrails for planning mechanisms and tool usage), before deployment (baseline safety testing covering tool usage patterns and workflow reliability), and after deployment (real-time monitoring with controls that can automatically reduce agent autonomy or pause execution when thresholds are crossed).[2]
Dimension 4: Enable End-User Responsibility. Organizations must provide sufficient transparency and training for end users to understand what AI agents do on their behalf, when to question agent behavior, and how to escalate concerns. End users are often the first line of detection for agent misbehavior that monitoring systems miss.
📋 Section Summary
- Singapore’s MGF (January 22, 2026) is the world’s first national governance framework for agentic AI — four dimensions covering risk bounding, human accountability, technical controls, and end-user responsibility.
- “While agents may act autonomously, human responsibility continues to apply” — accountability does not transfer to the agent; named humans remain responsible regardless of autonomy level.
- Technical controls must span three lifecycle stages: development, deployment, and production — post-deployment monitoring alone, the most common implementation pattern, is insufficient.
Practical Controls: Five Things to Build Before Deploying
Singapore’s MGF provides the governance skeleton. The following controls are what enterprise programs need to build on top of it.
🔒 Control 1: Permission Boundaries and Least-Privilege Agent Identity
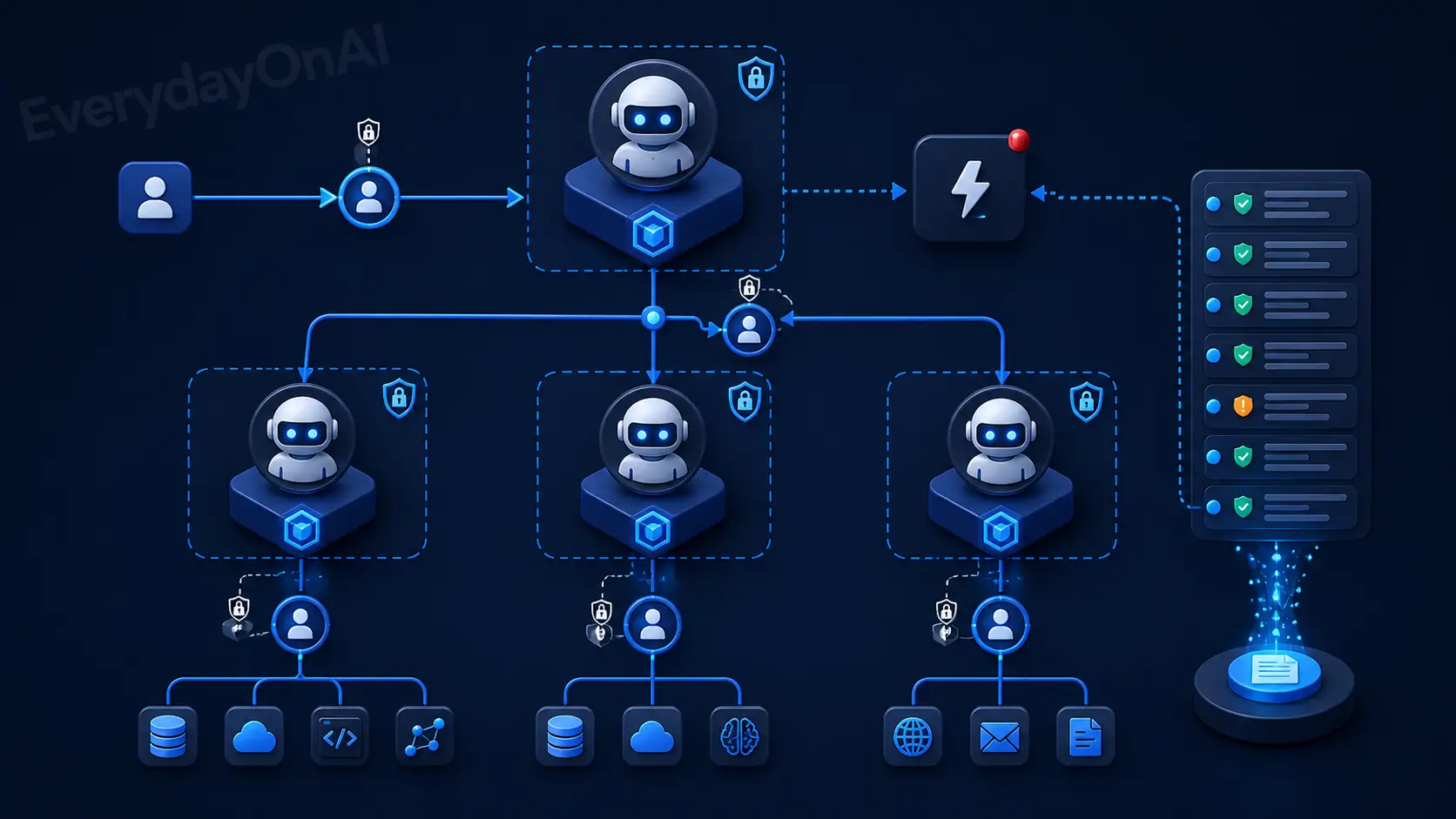
Every deployed agent should have a defined permission set implemented at the infrastructure level — not just as agent instructions — specifying: which data sources it can read, which systems it can write to, which external APIs it can call, maximum transaction values it can authorize, and which actions require human approval before execution. Unique agent IDs tied to named supervising humans create the accountability chain the MGF requires. Treat agent identity as a pre-deployment blocker for high-autonomy agents.
📊 Control 2: Action Classification and Approval Tiers
Classify all actions an agent may take into three tiers by reversibility and impact: Tier A (irreversible or high-value) — mandatory human approval before execution. Tier B (reversible but significant) — automated execution with immediate human notification and review window. Tier C (routine reversible) — automated execution with logging. This classification is the foundation that makes HITL tractable: instead of reviewing every action, humans review only the actions that genuinely require judgment.
📋 Control 3: Whitelisted Tool and Service Registry
Maintain an approved service registry for all external services, APIs, and MCP servers agents are authorized to interact with. Agents should be technically prevented from calling services not in the registry. Registry entries include: data access scope, security review date, governance approval record, and cryptographic hash verification of tool descriptions for MCP servers. Third-party MCP servers require documentation review and hash verification before registry inclusion to detect tampering.
🎪 Control 4: Prompt Injection Hardening
For agents processing external content — emails, web pages, API responses, documents — implement input sanitization that prevents external content from introducing instruction triggers into the agent’s context. Treat all external content as untrusted by default. Separate the agent’s instruction context from processed content. The OWASP GenAI Security Project’s 2026 guides on MCP server security provide the most detailed current guidance for teams building agents with tool use.
⚠ Control 5: Circuit Breakers and Autonomy Throttling
Implement automated circuit breakers that pause execution or reduce autonomy when: action volume exceeds defined thresholds in a time period, actions of a specific type reach daily/hourly limits, error rate crosses a defined threshold, or HITL review queue exceeds available capacity. Circuit breakers prevent runaway agent behavior and ensure that when oversight becomes ineffective, the system fails safely rather than continuing without genuine accountability. This is the technical implementation of the “can you shut it down?” test — the answer must be yes, with a documented procedure.

Human-in-the-Loop: Making Oversight Real, Not Nominal
66% of enterprise leaders find building genuine HITL checkpoints technically difficult, and most are settling for a more passive “human-on-the-loop” model instead — monitoring that can theoretically intervene but typically doesn’t.[7] The distinction matters because human-on-the-loop fails predictably as agents become more numerous and action queues grow faster than reviewers can process.
Meaningful HITL requires three operational conditions.
Condition 1: Reviewers must have sufficient context. A reviewer seeing only “I sent this email to the customer” cannot evaluate whether that action was appropriate. Meaningful review requires: the initiating task, the agent’s reasoning steps, the specific action, and downstream consequences. Governance must specify what context reviewers receive — and technical infrastructure must make it accessible without requiring them to dig through logs.
Condition 2: Review must occur before irreversibility, not after. For Tier A actions, review is a gate before execution. For Tier B actions, the review window (time between notification and irreversibility) must be sufficient for genuine review. If the window for a payment action is two minutes and the reviewer is in a different time zone, the control is not functioning as designed.
Condition 3: Automation bias must be actively monitored. Monitor HITL override rates over time. A progressive decline in override rates for a specific agent or action type signals that reviewers are over-trusting the agent rather than evaluating each action. When override rates drop below a defined threshold, trigger a review of whether oversight is still effective. Periodic adversarial testing — deliberately introducing incorrect agent outputs to verify reviewers catch them — is the most reliable mechanism for validating that oversight quality hasn’t degraded.
Action Audit Trails: Governing What Agents Do
Conventional AI audit trails record what a model recommended. Agentic AI audit trails must record what an agent did. A complete agent action audit trail contains: the task that initiated agent execution (including the human or system that authorized it), every reasoning step the agent took, every tool call and its parameters, every external service interaction and response, every action taken (including blocked attempts), human review decisions with reviewer identity and timestamp, and final outcomes in external systems.
This level of logging is non-negotiable for two reasons. Regulatory: the EU AI Act’s Article 12 logging requirements for high-risk AI specify that logging must enable behavioral reconstruction — which for agents requires action-level, not just output-level, logs. Operational: when an agent causes an incident, investigation requires a complete action-level audit trail to determine exactly what happened, when, and what triggered it. Without it, incidents cannot be properly investigated, liability cannot be assessed, and governance program improvements cannot be grounded in evidence.
For the governance tools that provide agent-level action logging and audit trail infrastructure, see our dedicated survey: Top 8 AI Governance Tools and Platforms to Watch in 2026–2027.
Where Singapore’s Framework Has Gaps — And How to Fill Them
“Singapore’s framework gives you a governance skeleton that maps cleanly to how enterprises already think about risk management. But in three critical areas, what it tells you is incomplete enough to create false confidence.”
— Rock Cyber Musings, “Agentic AI Governance: Singapore Built the Skeleton, Not the Immune System,” February 2026[4]
Gap 1: Agent identity is treated as “evolving.” The framework’s interim best practices — unique agent IDs, recording delegation, tying identity to supervising humans — are reasonable temporary measures. But until agent-native identity primitives exist, the entire accountability chain is structurally unsound. Enterprise programs should treat agent identity as a pre-deployment blocker for high-autonomy agents. Use task-scoped ephemeral credentials where possible; implement cryptographically verifiable identity for agents with persistent operational contexts.[4]
Gap 2: MCP security is dramatically underspecified. The entire MCP security guidance in Singapore’s MGF is two bullet points. For organizations using MCP — which reached 97 million downloads within months of release[9] and is rapidly becoming the standard interface between AI agents and external tools — this is insufficient. Fill this gap with OWASP GenAI Security Project’s 2026 MCP guides: require developers to submit third-party MCP servers with documentation and cryptographic hash verification before registry inclusion.
Gap 3: Multi-agent system governance is not addressed. The MGF focuses on single-agent deployments. Most enterprise agentic AI deployments involve multiple agents with orchestrator-worker relationships, delegation chains, and tool-sharing. Treat each agent-to-agent trust boundary as an additional governance checkpoint, with explicit authorization models for what each agent is permitted to delegate to which other agents.
📋 Section Summary
- Three gaps in Singapore’s MGF require supplemental enterprise controls: agent identity (treat as pre-deployment blocker for high-autonomy agents), MCP security (OWASP GenAI 2026 guides), and multi-agent governance (agent-to-agent trust boundaries as governance checkpoints).
- MCP’s rapid adoption (97 million downloads, 1,000+ servers) makes MCP server security a pressing gap — the brief two-bullet-point treatment in the MGF is insufficient for organizations actively deploying MCP-connected agents.
- The gaps are not criticisms of the MGF’s quality — they reflect that the framework was published in January 2026 for a deployment landscape that is still actively developing. Treat the MGF as a floor, not a ceiling.
Before & After: Deploy First vs. Govern First
✖ Deploy First
An enterprise deploys an AI agent for customer payment processing without a formal permission boundary or action classification tier. The agent processes payments as designed for six weeks. On week seven, a configuration error causes the agent to execute duplicate payments for a subset of customers. With no circuit breaker, 847 duplicate transactions occur before a customer complaint reaches the right team. Investigation takes 11 days because there is no action-level audit trail.
✔ Govern First
The same payment agent has a Tier A classification for all transactions above $500 (requiring approval before execution), a circuit breaker that triggers after 3 transactions of the same type within 60 seconds, and a complete action audit trail. The configuration error triggers the circuit breaker after 3 duplicate transactions. The agent pauses. An alert reaches the named system owner. Investigation takes 2 hours. 3 transactions are reversed instead of 847.
✖ Nominal HITL
An enterprise marks all agent email communications as “Tier B — human notification.” Reviewers receive notifications but process them in batches at the end of the day. The queue grows. Within two months, reviewers are processing notifications for emails sent 6 hours ago. The review is no longer functioning as oversight — it is post-hoc documentation of actions that are long since irreversible.
✔ Operational HITL
The same communications are classified by reversibility: routine templated responses are Tier C (logged only), non-templated responses above a defined sensitivity threshold are Tier A (blocked until review). Circuit breaker activates if the Tier A queue exceeds 20 items, reducing agent autonomy until reviewers clear the backlog. Override rates are monitored monthly as an automation bias signal.
Tool: Agentic AI Governance Readiness Check
🎯 Interactive Tool
Agentic AI Governance Readiness Check
Check every statement that’s currently true for your deployed or planned AI agent(s). Based on the five controls and HITL requirements from this guide.
This is a directional self-assessment based on the controls covered in this guide. Actual governance readiness depends on implementation quality, not just checklist completion — a nominal permission boundary that agents can bypass is not a pass.
Related articles in the Enterprise AI Governance Series:
- → AI Governance for Enterprise: Policy to Operational Readiness (Pillar)
- → What Does a Chief AI Officer (CAIO) Actually Do?
- → How to Build an AI Governance Committee
- → Algorithmic Bias Audit: EU AI Act and NYC Requirements
- → ISO 42001 vs. NIST AI RMF: Which Standard Should You Start With?
- → Top 8 AI Governance Tools in 2026–2027
- → AI Governance as Competitive Advantage
Frequently Asked Questions
What is agentic AI governance?
The controls, accountability structures, and oversight mechanisms that ensure AI agents operate within defined boundaries with auditable, human-accountable actions. It extends conventional AI governance to address actions (not just recommendations), continuous operation (not just decision points), and cascading failures in multi-agent environments that conventional AI governance wasn’t designed for. Singapore’s IMDA MGF (January 22, 2026) is the most comprehensive current public guidance, supplemented by enterprise controls for agent identity, MCP security, and multi-agent governance.
What is Singapore’s MGF for Agentic AI?
The world’s first national governance framework for AI agents — launched at Davos, January 22, 2026.[1] Four dimensions: assessing and bounding risks upfront, making humans meaningfully accountable, implementing technical controls across the agent lifecycle, and enabling end-user responsibility. Voluntary but the most comprehensive publicly available agentic AI governance guidance in 2026. Enterprise programs should supplement it with controls for agent identity, MCP server security, and multi-agent system governance — three documented gaps the framework doesn’t fully address.
What are the biggest governance risks of agentic AI?
Five categories: unauthorized or erroneous actions, automation bias in oversight, prompt injection at action scale, scope creep/goal misalignment, and data breach through agent connectivity.[2] Each requires distinct controls. The governance indicator most enterprises fail: 35% cannot shut down a rogue AI agent if one emerged — the most concrete single test of operational governance readiness.[8]
How do you implement human-in-the-loop for agentic AI?
Through action classification and tiered oversight, not blanket review. Classify actions by reversibility and impact into Tier A (approval gate before execution), Tier B (notification with review window), and Tier C (log only). Three conditions make HITL genuine: reviewers have sufficient context, review occurs before irreversibility for Tier A, and automation bias is actively monitored via override rate tracking. 66% of enterprise leaders find building genuine HITL technically difficult and settle for less effective human-on-the-loop models instead.[7]
Why do most agentic AI projects fail to reach production?
88% fail to reach production — with governance and security bottlenecks cited in 38-67% of stalled projects.[9] The root causes: insufficient infrastructure and data integration (41%), inadequate governance and security including identity management and audit logging (38-67%), and missing baseline metrics before pilots (28-33%). The 12% that succeed share four attributes: pre-deployment infrastructure investment, governance documentation before deployment, baseline metrics established before pilots, and dedicated business ownership with post-deployment accountability. Organizations using AI governance tools get 12x more projects into production.[10]
📚 References and Sources
- Singapore IMDA, “Model AI Governance Framework for Agentic AI,” January 22, 2026. Four governance dimensions; announcement at WEF Davos; quote from April Chin. imda.gov.sg
- Singapore IMDA, MGF for Agentic AI (full document). BCG cascading failure analysis; data breach risk category; technical controls; Dimension 2 “human responsibility continues to apply.” imda.gov.sg (PDF)
- Baker McKenzie, “Singapore: Governance Framework for Agentic AI Launched,” January 2026. Framework overview; four dimensions; use-case risk assessment recommendations. bakermckenzie.com
- Rock Cyber Musings, “Agentic AI Governance: Singapore Built the Skeleton, Not the Immune System,” February 2026. Three framework gaps: agent identity, MCP security, multi-agent governance; prompt injection at action scale. rockcybermusings.com
- Bird & Bird, “Singapore Introduces New Model AI Governance Framework for Agentic AI,” January 2026. MGF voluntary status; accountability scope. twobirds.com
- AI Asia Pacific Institute, “Governing AI That Acts,” January 2026. Stability-Assured Framework (SAFE); sandboxing, monitoring, escalation protocols. aiasiapacific.org
- OutSystems, “2026 State of AI Development Report” (survey of 1,879 IT leaders), April 2026. 97% exploring agentic AI; only 12% use centralized governance platform; 41% rely on project-level rules only; 66% find HITL technically difficult; majority settling for human-on-the-loop. techhq.com
- Writer research (2026) and Deloitte (2026), cited in Evolvance Market Research, “AI Governance Statistics 2026.” 35% of organizations admit they cannot shut down a rogue AI agent; only 21% have mature governance model for autonomous agents (Deloitte). evolvancemarketresearch.com
- Digital Applied, “Agentic AI Statistics 2026: 150+ Data Points Collection,” March 2026. 88% project failure rate; governance and security in 38-67% of stalled projects; MCP 97 million downloads; 171% median ROI for production deployments; four attributes of the 12% that succeed. digitalapplied.com
- Databricks, “Enterprise AI Agent Trends: Top Use Cases, Governance + Evaluations,” 2026 State of AI Agents (20,000+ organizations). Organizations using AI governance tools achieve 12x more AI projects into production; organizations using evaluation tools move 6x more AI systems to production. databricks.com
Sources verified June 21, 2026. Agentic AI governance guidance is evolving rapidly — the Singapore MGF was published January 2026 and may be updated. Check imda.gov.sg for the most current version. This article does not constitute legal advice.
💬 According to EverydayOnAI
The 12x production success rate from the Databricks data is the figure that should end the “governance slows us down” argument in every enterprise AI team. The 88% that fail never reach the 171% ROI that the 12% capture — and the root cause in 38-67% of stalled projects is governance and security gaps, not capability or talent gaps. The organizations treating governance as an obstacle to deployment are the ones generating the failure rate statistics that make this space look hard. The organizations treating governance as the deployment infrastructure are the ones capturing the returns. This playbook is built for the second group.
Download the Agentic AI Governance Playbook
Pre-deployment checklist, permission boundary template, action classification framework (Tier A/B/C), HITL protocol design guide, action audit trail specification, and MCP server registry template — built on Singapore’s MGF with enterprise-grade controls for 2026 production deployments.
Share this article